
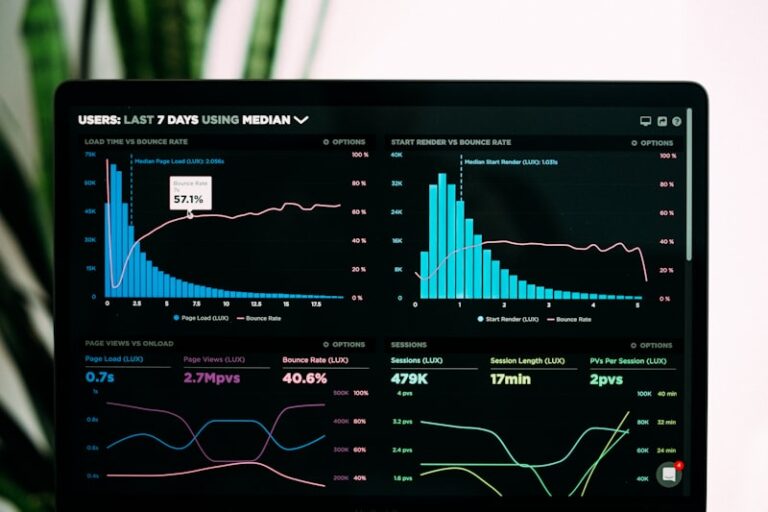
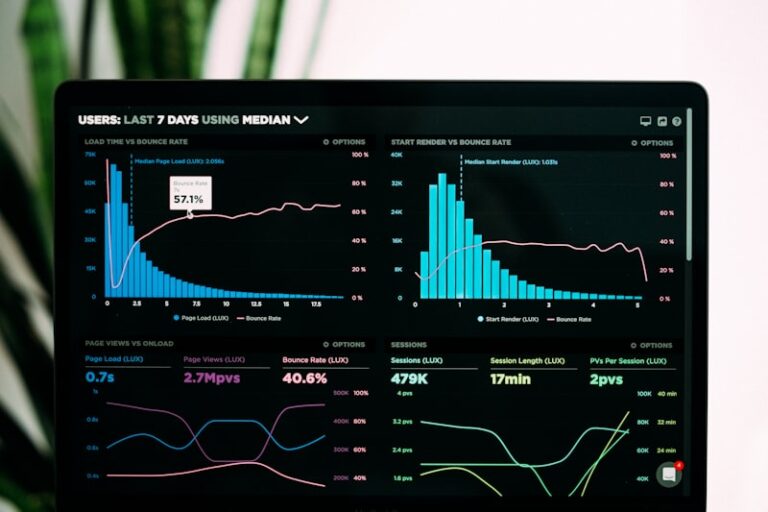
DFFITS: Detecting Influential Data in Psychological Models
DFFITS: A Measure of Influence in Regression Analysis The Core Definition of DFFITS DFFITS, an acronym standing for Difference in Fitted Values, is a highly critical diagnostic tool employed extensively in the field of regression analysis. Its primary purpose is to identify observations within a dataset that exert an unusually large influence on the prediction […]
Resistant Estimators: Mastering Data Against Bias
The Resistant Estimator in Statistics and Data Science The Core Definition of Resistant Estimators The resistant estimator is a specialized class of statistical tools developed for the purpose of accurate parameter estimation, particularly designed to minimize the influence of spurious data points or irregularities. At its core, a resistant estimator is defined by its robustness; […]
Statistical Resilience: Bridging Data and Human Recovery
Robust Estimator, Resocialization Introduction to Robust Estimators and Resocialization The realms of quantitative analysis and social intervention often grapple with complexity, requiring specialized approaches to yield reliable insights and foster positive change. Within this intricate landscape, two distinct yet equally vital concepts emerge: the robust estimator in statistics and resocialization in sociology and psychology. While […]
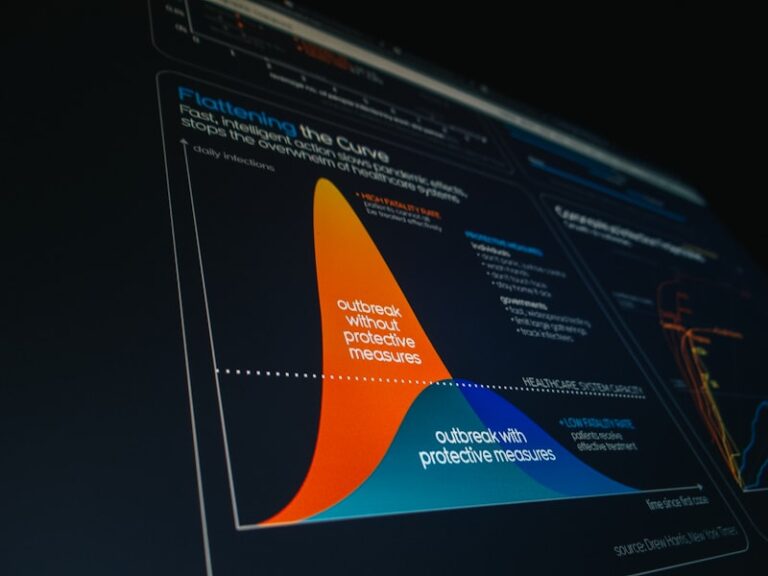
Statistical Outliers: Unmasking Hidden Data Biases
Counternull Value: A Statistical Technique for Outlier Detection Introduction to Outlier Detection In the vast landscape of data analysis, the integrity and reliability of datasets are paramount for drawing accurate conclusions and making informed decisions. One significant challenge that researchers and analysts frequently encounter is the presence of outliers. Outliers are data points that deviate […]
FREQUENCY ANALYSIS
FREQUENCY ANALYSIS Conceptual Foundations of Frequency Analysis Frequency analysis represents a cornerstone statistical method designed to systematically quantify, categorize, and evaluate the recurrence rate of specific values, events, or categorical variables within a designated dataset. By meticulously tracking how often each distinct data point manifests, this analytical technique reveals the underlying distribution of the data, […]
COOK’S D
An Introduction to Cook’s Distance in Statistical Diagnostics In the field of statistics and psychometrics, Cook’s D, or Cook’s distance, stands as one of the most critical diagnostic tools for evaluating the integrity of a linear regression model. Developed by R. Dennis Cook in the late 1970s, this statistic provides a comprehensive measure of the […]
MAHALANOBIS I)
Historical Origins and the Vision of Prasanta Chandra Mahalanobis The concept of the Mahalanobis distance (MD) stands as a cornerstone in the field of multivariate statistics, representing a significant departure from traditional univariate measures of distance. It was first introduced in 1936 by the eminent Indian statistician and biologist Prasanta Chandra Mahalanobis (1893-1972), whose contributions […]
INTERQUARTILE RANGE
Introduction to the Interquartile Range as a Statistical Pillar In the expansive field of descriptive statistics, the Interquartile Range (IQR) serves as a critical metric for understanding the spread and variability of a data set. While measures of central tendency, such as the mean, median, and mode, provide a snapshot of the “center” of a […]