
Likelihood: Measuring Truth in Behavioral Data
Defining Likelihood in Statistical and Psychological Contexts The concept of likelihood is fundamental to statistical inference and plays a critical role in how researchers in psychology evaluate hypotheses and model complex behavioral data. Formally, likelihood quantifies the plausibility of a specific set of hypothesized parameters, given that a particular set of observed data has occurred. […]

Sufficient Statistics: Data Reduction for Mental Models
Introduction: Defining the Sufficient Statistic In the expansive field of mathematical statistics, the concept of a sufficient statistic holds immense theoretical and practical importance, particularly concerning the efficiency and integrity of parameter estimation. Fundamentally, a sufficient statistic is a function of the observed sample data that encapsulates all the information available in that sample regarding […]

Mixed-Effects Models: Unlocking Hidden Patterns in Data
Defining the Mixed-Effects Model (Core Concepts) The mixed-effects model represents a fundamental advancement in statistical methodology, particularly within the fields of psychology, biology, and social sciences, where data often exhibit complex, non-independent structures. This sophisticated modeling framework is specifically designed for the evaluation of variance when an experimenter assumes that some predictor variables are fixed […]
Prediction Intervals: Forecasting Individual Human Behavior
Definition and Fundamental Concept of the Prediction Interval The prediction interval (PI) is a statistical construct central to applied regression analysis, particularly within fields such as psychology where forecasting individual outcomes based on established relationships is paramount. Fundamentally, the prediction interval defines a specific range of values within which a single, future observation of a […]
Normality Testing: Is Your Data Normal?
Introduction and Core Definition The Shapiro-Wilks test is a sophisticated statistical procedure specifically designed to test the fundamental hypothesis that a given sample of data originated from a population characterized by a normal distribution, often visualized as the classic bell curve. This test occupies a pivotal position in inferential statistics because the validity of many […]
Posterior Distribution: Updating Beliefs with Bayesian Data
Conceptual Foundation of the Posterior Distribution The posterior distribution stands as a central, defining concept within the framework of Bayesian statistical analysis, particularly as applied across the diverse fields of psychological science and cognitive modeling. Fundamentally, it represents the updated state of knowledge regarding the parameters of interest after observing new empirical data. In formal […]

Standard Error: Measuring Precision in Psychological Data
Introduction and Core Definition The concept of the Standard Error (SE) is foundational to inferential statistics and plays a critical role in psychological research, serving as the essential measure of the precision and reliability of a sample statistic. Formally, the standard error is defined as the standard deviation of a sampling distribution. This definition is […]

Confidence Limits: Mapping the Boundaries of Human Certainty
Confidence Limits The Core Definition of Confidence Limits Confidence limits represent the boundary values—the upper and lower resulting points—of a Confidence Interval. These limits define a specific range within which the true value of a specific population Parameter is expected to exist, based on the collected sample data and a recognized level of likelihood or […]
Statistical Error: Why Data Never Tells the Whole Story
Statistical Error in Psychological Research The Core Definition of Statistical Error A statistical error, within the context of psychological and scientific research, refers primarily to the inevitable discrepancy between a measured value (derived from a sample) and the true, underlying parameter of the population being studied. It is crucial to understand that a statistical error […]
Statistical Estimation: Decoding Hidden Patterns of Mind
Estimator in Psychology and Statistics The Core Definition of an Estimator The concept of an estimator is fundamental to the field of statistical inference, serving as the bridge between observable sample data and unobservable characteristics of a larger population. Fundamentally, an estimator is a rule, usually expressed as a mathematical formula, which dictates how data […]
Simultaneous Confidence Intervals: Precision in Data Analysis
Simultaneous Confidence Intervals in Psychology The Core Definition of Simultaneous Confidence Intervals Simultaneous Confidence Intervals (SCIs) represent a sophisticated statistical technique employed primarily in data analysis to estimate multiple population parameters concurrently from a single dataset. Unlike a standard, or marginal, Confidence Interval, which guarantees a specified level of confidence for only a single parameter […]
Statistical Correlation: Mastering Fisher’s Transformation
FISHER’S R TO Z TRANSFORMATION The Core Definition The Fisher’s r to z transformation is a vital statistical technique employed primarily to address the non-normality inherent in the sampling distribution of the Pearson product-moment correlation coefficient, commonly denoted as $r$. This transformation converts the sample correlation coefficient $r$ into a new variable, often symbolized as […]

Non-Parametric Statistics: Powerful Tools for Real Data
Distribution-Free Tests: A Comprehensive Encyclopedia Entry The Core Definition of Distribution-Free Tests A distribution-free test, commonly referred to as a non-parametric test, constitutes a critical category of statistical procedures that enable researchers to perform valid statistical inferences about a population without requiring specific assumptions regarding the precise probability distribution of the data. This approach represents […]

Representativeness: Why Your Sample Matters More Than Ever
Representativeness in Psychological Research The Core Definition of Representativeness In the context of psychological and statistical research, representativeness refers to the critical extent to which a chosen sample of participants or data accurately reflects the larger population from which it was drawn. This concept is foundational to sound scientific methodology because the goal of most […]

Statistical Significance: Beyond the P-Value
Significance Testing Introduction to Significance Testing Significance testing, frequently known as hypothesis testing, constitutes a fundamental methodological framework within statistics, meticulously designed to evaluate claims about population parameters using data collected from samples. Its overarching purpose is to discern the probability that an observed relationship, difference, or effect between two or more variables within a […]

Maximum Likelihood: Predicting Human Behavior Through Data
Maximum Likelihood Introduction to Maximum Likelihood Maximum likelihood estimation (ML), often abbreviated as ML, stands as a cornerstone method in the field of statistical inference. At its core, it is a sophisticated technique employed for estimating the parameters of a given probability distribution or statistical model, based on observed data. The fundamental principle revolves around […]
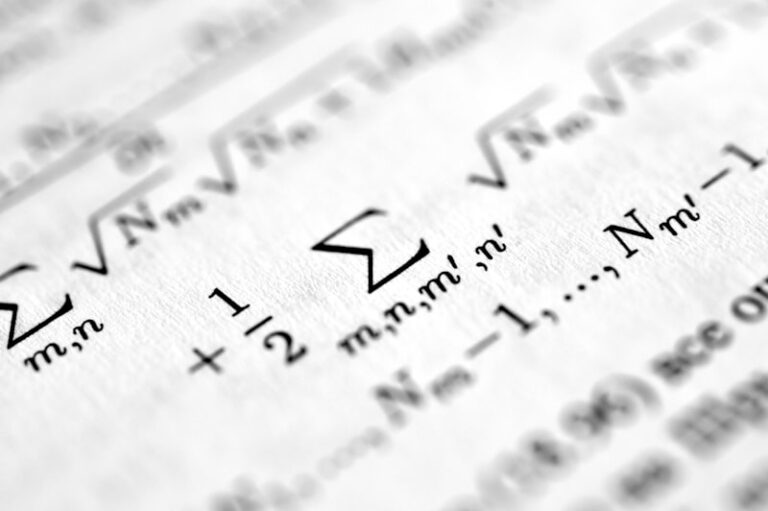
Nuisance Parameters: Mastering Variables in Research
Nuisance Parameter Introduction to Nuisance Parameters in Psychological Research In the intricate world of psychological research methods, scientists strive to uncover the true relationships between variables, such as the effectiveness of a new therapeutic intervention or the cognitive processes underlying decision-making. However, the complexity of human behavior and mental states means that many factors can […]
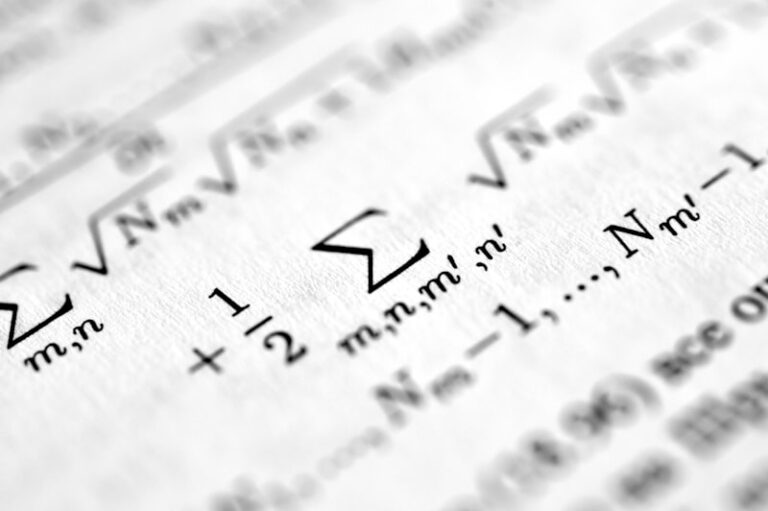
Noncentral F-Distribution: Decoding Statistical Power
The Noncentral F-Distribution The Core Definition The noncentral F-distribution is a fundamental probability distribution in statistical inference, serving as a powerful analytical tool for situations where the null hypothesis of equal population means is not assumed to be true. It represents a generalization of the more commonly known F-distribution, which primarily describes the ratio of […]
LIKELIHOOD PRINCIPLE
Likelihood Principle is a statistical principle which states that the best estimate of a parameter is the value that maximizes the likelihood function. This principle is commonly used to estimate parameters for statistical models such as logistic regression, linear regression, and Poisson regression. The likelihood principle is a fundamental tool in the fields of statistics, […]
BAYES’ THEOREM
The Historical and Theoretical Foundations of Bayes’ Theorem Bayes’ Theorem represents a cornerstone of modern statistical theory, providing a rigorous mathematical framework for updating the probability of a hypothesis as more evidence or information becomes available. Named after the 18th-century English Presbyterian minister and mathematician Thomas Bayes, the theorem was originally formulated to address the […]
UNBIASED
Unbiased Estimation of Population Parameters: A Review Abstract This article reviews the concept of unbiased estimation of population parameters. Unbiased estimation is a method of estimating the population parameters of a given data set that avoids bias in the estimation process. The article defines unbiased estimation and summarizes the different types of unbiased estimators commonly […]
WALD-WOLFOWITZ TEST
Historical Development and Theoretical Origin of the Wald-Wolfowitz Test The Wald-Wolfowitz test, also known as the Runs Test for two samples, represents a foundational development in the field of nonparametric statistics. It was originally proposed in 1940 by Abraham Wald and Jacob Wolfowitz, two of the most influential statisticians of the twentieth century. Their work […]
UNBIASED ESTIMATOR OF VARIANCE
Introduction to Statistical Variance The concept of variance stands as a fundamental pillar within statistical theory, serving as the primary metric for quantifying the dispersion or spread within a set of data points. In practical terms, variance measures how far individual observations in a data set tend to deviate from the central tendency, typically represented […]
BEHRENS-FISHER PROBLEM
Introduction to the Behrens-Fisher Problem The Behrens-Fisher problem stands as one of the most enduring and conceptually challenging issues within classical statistical inference. At its core, the problem addresses the task of determining whether the means of two independent populations, both assumed to follow a normal distribution, are significantly different from one another. While this […]
RANDOMIZATION TEST
Introduction and Fundamental Definition The randomization test, often synonymously referred to as the permutation test, constitutes a powerful and flexible class of non-parametric statistical methods used for hypothesis testing. Unlike traditional parametric tests, such as the independent samples t-test or ANOVA, which rely on specific assumptions regarding the underlying population distribution (most notably normality and […]