Frequency Tables: Mapping Patterns in Human Behavior
Introduction and Definition of the Frequency Table A frequency table constitutes a fundamental organizational tool within descriptive statistics, serving as a systematic method for summarizing the distribution of data. At its core, a frequency table is defined as a numerical summary that meticulously records the frequency of occurrences for specific values or ranges of values […]

Likelihood: Measuring Truth in Behavioral Data
Defining Likelihood in Statistical and Psychological Contexts The concept of likelihood is fundamental to statistical inference and plays a critical role in how researchers in psychology evaluate hypotheses and model complex behavioral data. Formally, likelihood quantifies the plausibility of a specific set of hypothesized parameters, given that a particular set of observed data has occurred. […]

Psychometric Cutoff: Navigating Thresholds in Assessment
Definition and Fundamental Concept The cutoff point, often termed a threshold or critical score, represents a fundamental concept in statistics, psychometrics, and diagnostic classification, particularly within the field of psychology. It is formally defined as a specific numeric value utilized to partition a continuous distribution of scores, measurements, or data into two distinct, mutually exclusive […]

Empirical Research: Unlocking Patterns in Human Behavior
Defining Data Analysis and Its Purpose Data analysis represents the fundamental procedural core of empirical research, involving the systematic application of numerical, statistical, or charted methodologies to a collected corpus of information. The primary objective of this procedure is to determine underlying patterns, identify standard trends, and effectively summarize the inherent characteristics of the data […]

Poisson Distribution: Predicting Rare Human Behaviors
The Poisson Distribution: Modeling Rare and Random Occurrences The Poisson distribution is a fundamental theoretical statistical distribution used extensively across natural, social, and psychological sciences. Named after the French mathematician Siméon Denis Poisson, this model provides the framework for calculating the likelihood that a specific number of events will occur within a fixed interval of […]
Cumulative Probability: Mapping Human Behavioral Patterns
Definition and Fundamental Characteristics of the Cumulative Probability Distribution The concept of the Cumulative Probability Distribution (CPD), often formalized mathematically as the Cumulative Distribution Function (CDF), represents a fundamental tool in both statistics and quantitative psychology for analyzing data sets and defining the likelihood of outcomes. At its core, the CPD provides a comprehensive summation […]

Cramer’s V: Measuring Associations in Psychological Data
CRAMER’S V COEFFICIENT: Definition and Overview Cramér’s V, often simply denoted as V, is a crucial measure utilized in statistics, particularly within the realm of non-parametric analysis, designed to quantify the strength of association or correlation between two nominal variables. This coefficient is an indispensable tool when analyzing data presented in contingency tables, which are […]

Expected Value: Mastering the Psychology of Risk Decisions
Definition and Fundamental Concepts The concept of Expected Value, often denoted as E[X] for a random variable X, stands as a cornerstone of probability theory and mathematical statistics. Fundamentally, the expected value represents the theoretical long-run average of the outcomes of a random experiment if that experiment were to be repeated an infinite number of […]

Statistical Correlation: Unlocking Hidden Behavioral Patterns
Defining Correlation and Correlates In the expansive field of psychological methodology and statistics, the term correlate serves a crucial dual function, operating both as a substantive noun describing an associated factor and an active verb describing the formal, statistical process of establishing that association. Fundamentally, a correlate is defined as any variable, phenomenon, or measurable […]
Unimodal Distributions: Finding the Peak in Human Data
Introduction and Definition of Unimodal Distribution The concept of a unimodal distribution is foundational to descriptive statistics and central to the analysis of empirical data across various scientific disciplines, particularly psychology. Fundamentally, a distribution is classified as unimodal if the set of data or ratings possesses exactly one mode, which is defined as the value […]
Sampling Distribution: The Bridge to Statistical Truth
Sampling Distribution: Definition and Foundational Concepts The concept of the sampling distribution of a statistic is fundamental to understanding all procedures within inferential statistics, serving as the theoretical bridge between sample data and population parameters. It is formally defined as the allocation of a given statistic, such as the mean, standard deviation, or proportion, for […]

Dependent Variable: Measuring Change in Psychological Research
Definition and Fundamental Role The Dependent Variable (DV) serves as the cornerstone of empirical investigation across the psychological and social sciences. Fundamentally, the DV is defined as the outcome variable that is observed, measured, and recorded following the manipulation or occurrence of the Independent Variable (IV). It represents the effect, change, or response that the […]
Statistical Kurtosis: Unveiling Hidden Data Patterns
Introduction and Fundamental Definition of Kurtosis Kurtosis is a crucial descriptive statistic in the analysis of probability distributions, providing insight into the shape and characteristics of a dataset beyond the simple measures of central tendency (mean) and dispersion (variance). Fundamentally, kurtosis is defined as the fourth central moment of a probability distribution, standardized by the […]
Binary Variables: Decoding Human Choices in Two States
Definition and Fundamental Characteristics A binary variable, often referred to as a dichotomous variable, is a fundamental concept in statistics and psychological measurement, defined by its inherent limitation to only two possible values or categories. This structure represents the simplest form of a categorical variable, where the two states are mutually exclusive and collectively exhaustive, […]

Psychological Percentiles: Measuring Your Relative Standing
Introduction and Definition of Percentiles The concept of a percentile is fundamental to descriptive statistics, particularly within psychological assessment and educational measurement, serving as a critical metric for understanding the relative standing of an individual score within a defined group distribution. Formally, a percentile is defined as the position of a score in a distribution […]

The Power Law: Why Success Follows Unfair Patterns
Introduction to the Power Law The concept of the Power Law represents a fundamental mathematical relationship observed across diverse fields of human endeavor and natural phenomena, notably within quantitative psychology and statistics. In this context, the Power Law is not a singular theorem but rather a descriptive generalization encompassing two critical areas: the relationship between […]

Psychological Precision: Mastering the Art of Consistency
Introduction and Core Definition of Precision The concept of precision, particularly within the scientific domain, serves fundamentally as a gauge of measurement correctness related to consistency. In its most basic definition, precision refers to the degree to which repeated measurements under unchanged conditions show the same results. It is a critical metric for evaluating the […]
Power Functions: How Mathematical Laws Shape Human Behavior
Introduction to the Power Function Concept The term Power Function holds significant dual meaning within the fields of mathematics, statistics, and consequently, psychology. Fundamentally, it describes a specific type of mathematical relationship where the value of one variable is determined by another variable raised to a specific exponent or power. This mathematical definition forms the […]

Experimental Design: Mastering Efficiency in Research
Introduction to Fractional Replication Design (FRD) The Fractional Replication Design (FRD) represents a powerful and often necessary methodology within experimental research, particularly when dealing with complex systems involving numerous independent variables, or factors. Fundamentally, FRD is defined as an experimental setup where researchers deliberately choose not to evaluate every possible combination of factor levels. Unlike […]

Skewed Distributions: Why Normal Doesn’t Define Human Behavior
Introduction and Definition of Asymmetrical Distribution An asymmetrical distribution, often referred to statistically as a skewed distribution, describes a fundamental characteristic of data where the frequency of scores above the mean is distinctly unequal to the frequency of scores below the mean. In contrast to the highly desirable normal distribution, which is perfectly symmetrical around […]
Statistical Variance: Measuring Behavioral Predictability
Introduction to the Concept of Sum of Squares The concept of the Sum of Squares (SS) is a foundational element across numerous quantitative disciplines, including mathematics, geometry, statistics, and computational science. At its most fundamental level, the Sum of Squares quantifies the total variation or dispersion within a set of data points relative to a […]

Decision Theory: Mastering the Art of Choice
Introduction to Decision Theory Decision theory serves as a fundamental framework within the social, behavioral, and quantitative sciences, providing systematic methods for analyzing how choices are made, particularly under conditions of uncertainty or risk. At its core, Decision Theory explains the intricate process of arriving at a final decision by modeling the potential outcomes, the […]
Probability Theory: Mapping the Architecture of Human Thought
The Probability Density Function (PDF) is a fundamental concept within probability theory and statistics, serving as the rigorous mathematical representation of a continuous probability distribution. Unlike discrete distributions, which assign distinct probabilities to countable outcomes, continuous distributions deal with variables that can take on any value within a specified range, such as time, height, or […]

Sufficient Statistics: Data Reduction for Mental Models
Introduction: Defining the Sufficient Statistic In the expansive field of mathematical statistics, the concept of a sufficient statistic holds immense theoretical and practical importance, particularly concerning the efficiency and integrity of parameter estimation. Fundamentally, a sufficient statistic is a function of the observed sample data that encapsulates all the information available in that sample regarding […]

Probability Distribution: Decoding Patterns in Human Behavior
Defining Probability Distribution Probability distribution is a foundational concept within statistics and quantitative psychology, representing a mathematical function that provides the probabilities of occurrence of different possible outcomes in an experiment or observational study. It serves as a comprehensive theoretical framework detailing how likely specific values or ranges of values are for a given variable, […]

Statistical Testing: Unlocking the Science of Human Behavior
Introduction and Definition of Statistical Tests A statistical test is formally defined as a mathematical technique used systematically to evaluate a hypothesis regarding a population parameter based on observations derived from a sample of that population. In the realm of scientific research, particularly within disciplines like psychology, biology, and sociology, statistical tests provide the necessary […]

Phi Coefficient: Measuring Binary Data in Psychology
Introduction and Conceptual Definition The Phi coefficient ($phi$) serves as a fundamental measure of association within quantitative research, specifically designed for situations involving two variables that are strictly dichotomous. A dichotomous variable is defined as one that can only take on two possible values, typically representing the presence or absence of a characteristic, a success […]

Statistical Covariance: Decoding Hidden Behavioral Patterns
Introduction and Formal Definition The Sum of Cross Products (SCP), often referred to in statistical literature as the Sum of Products of Deviations, is a fundamental measure used to quantify the degree and direction of linear association between two distinct sets of variables, typically denoted as X and Y. This statistic serves as the essential […]

Autocorrelation: Unlocking Patterns in Mental Data
Defining Autocorrelation: The Core Concept Autocorrelation, fundamentally a measure derived from time series analysis and experimental statistics, refers to the statistical phenomenon wherein observations taken sequentially are correlated with themselves over time. In a rigorous statistical sense, it quantifies the degree of linear relationship between a variable’s current value and its past, or “lagged,” values. […]

Psychological Statistics: Decoding the Human Mind
Introduction and Definitional Framework Statistics is fundamentally defined as the branch of mathematics concerned with the careful collection, meticulous organization, insightful analysis, rigorous interpretation, and effective presentation of data. Within the scientific domain, and particularly in the complex field of psychology, statistics serves as the indispensable toolkit necessary for transitioning from raw, empirical observation to […]
Stanine: Mastering Your Data With This 9-Point Scale
a division of scores into 9 parts with a normal distribution. The mean of this scale is 5 with the standard deviation of 2. Educational performance can be assessed by this scale. STANINE: “A stanine is a division of scores into 9 parts with a normal distribution. The mean is 5 with deviation of 2.”

Psychological Permutation: Why Order Shapes Your Reality
The term permutation, originating from the field of combinatorics, is fundamentally defined within psychology as an arranged chain of components derived from a defined set, where the order of selection or placement is critically important. Unlike a simple combination, a permutation specifically addresses the sequence of elements, meaning that the arrangement ABC is distinct and […]

Platykurtic: Understanding Data Flatness in Psychology
PLATYKURTIC: Introduction and Definition The term platykurtic is utilized in descriptive statistics to characterize a distribution of scores that is significantly flatter than the standard normal distribution, often referred to as the mesokurtic curve. This designation is crucial for researchers in psychology and social sciences, as it provides immediate insight into the manner in which […]

Psychological Aggregation: Decoding Patterns in Human Data
Introduction to Aggregation: Dual Definitions The concept of aggregation is foundational across both the social sciences and quantitative methodologies, serving primarily to denote a collection of distinct elements—whether individuals or data points—that are unified by spatial proximity or a defined methodological grouping, rather than by intrinsic structural organization or shared intentionality. This term holds a […]
Suppressor Variables: Unmasking Hidden Data Insights
Introduction to the Suppressor Variable Concept The concept of the suppressor variable holds significant importance within statistical modeling, particularly in disciplines such as psychology, sociology, and econometrics, where researchers frequently analyze complex multivariate relationships. Unlike confounding variables, which artificially inflate or distort a relationship, a suppressor variable obscures or minimizes the true relationship between two […]
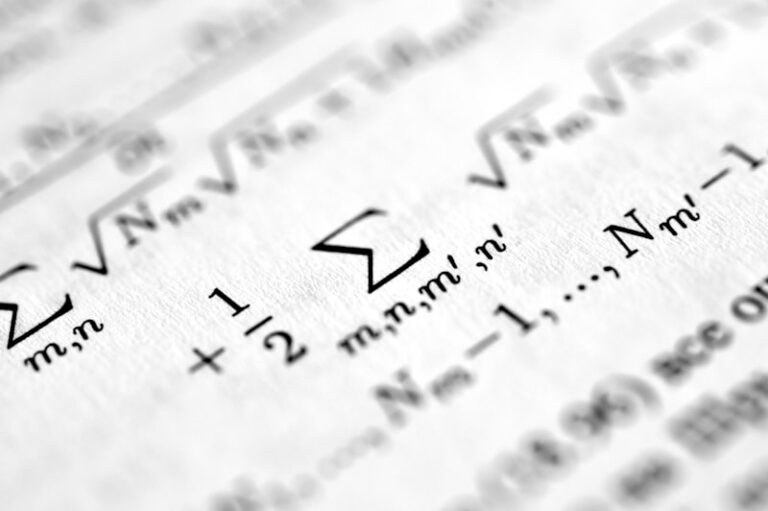
Sphericity: Master Your Statistical Assumptions
Introduction to Sphericity and its Context Sphericity stands as a fundamental statistical assumption critical to the appropriate application and interpretation of specific parametric tests, most notably the Repeated Measures Analysis of Variance (RM-ANOVA). This assumption governs the structure of the population variance-covariance matrix when a dependent variable is measured on the same experimental units—typically individuals—on […]
Asymptotic Normality: The Secret to Reliable Data Insights
ASSYMPTOTIC NORMALITY: Definition and Theoretical Foundations Asymptotic normality is a fundamental property within mathematical statistics, essential for modern statistical inference, particularly in fields like psychology, economics, and biostatistics where large datasets are common. This property describes a process whereby the distribution of a statistic, typically an estimator derived from a sample, gradually converges towards the […]
Psychological Midpoint: Finding Balance in Your Data
Definition and Fundamental Calculation The concept of the midpoint is foundational across mathematics, statistics, and psychological measurement, serving as a critical reference point defined by the extremities of a range. Formally, the midpoint is the integer or value situated precisely halfway between the maximum observed value and the minimum observed value within a specified set […]

Cumulative Frequency: Unlocking Patterns in Mental Data
Introduction to Cumulative Frequency Distribution The concept of a Cumulative Frequency Distribution (CFD) is fundamental to descriptive statistics, providing a powerful method for summarizing and interpreting large datasets, particularly those encountered in psychological research, educational assessment, and quality control. At its core, a CFD is a tabulation or graphical representation that illustrates the running total […]
Mesokurtic Distributions: Decoding the Normal Curve
Introduction to Mesokurtic Distributions The term mesokurtic is a fundamental concept within descriptive statistics and psychometrics, specifically referring to a distribution curve that exhibits a moderate level of peakedness and tail weight. Essentially, a distribution is classified as mesokurtic when its kurtosis—a measure of the shape of the probability distribution’s tails and shoulders—is neither significantly […]

Central Tendency: Finding the Typical Psychological State
Introduction and Definition of Measure of Location A measure of location, often referred to synonymously as a measure of central tendency, constitutes any class of statistical indices specifically designed to describe the central or typical point of a data distribution. These statistical measures are fundamental tools in descriptive statistics, providing a singular, representative value that […]
Mean Deviation: Quantifying Variability in Human Behavior
Introduction to Mean Deviation The concept of Mean Deviation (MD), often referred to as the Average Absolute Deviation, is a fundamental measure of dispersion utilized across various quantitative disciplines, including statistics, economics, and psychological research. It serves as an essential tool for quantifying the variability or spread within a given set of numerical data. Dispersion […]
Behavioral Trends: Mapping the Direction of Your Growth
Definition and Mathematical Foundation The concept of slope, fundamentally derived from mathematics and statistics, serves as a critical measure for quantifying the relationship between two variables. Technically defined as the ratio of the rise to the run, slope represents the change in the vertical distance ($Delta y$) divided by the corresponding change in the horizontal […]

Multivariate Analysis: Unlocking Complex Human Behavior
Defining Multivariate Analysis (The Core Concept) The term multivariate fundamentally defines any statistical methodology that involves the simultaneous observation and analysis of more than one outcome variable. In the context of psychological research and statistics, the use of multivariate techniques implies a necessary departure from simpler, two-variable relationships, moving toward the modeling of complex systems […]

Stochastic Independence: Why Randomness Matters in Thought
The Fundamental Concept of Stochastic Independence Stochastic independence describes a fundamental state within probability theory and statistics where the occurrence or non-occurrence of one event or the value taken by one random variable provides absolutely no discernible information about the occurrence or value of another event or variable. This condition means two systems or processes […]

Standard Error: Measuring Precision in Psychological Data
Introduction and Core Definition The concept of the Standard Error (SE) is foundational to inferential statistics and plays a critical role in psychological research, serving as the essential measure of the precision and reliability of a sample statistic. Formally, the standard error is defined as the standard deviation of a sampling distribution. This definition is […]

Statistical Dispersion: Mastering Data Variability
Average Absolute Deviation Introduction and Core Definition The Average Absolute Deviation (AAD), often interchangeably referred to as the Mean Absolute Deviation (MAD), is a fundamental measure in descriptive statistics that quantifies the amount of variability or dispersion within a set of data points. It represents the average distance between each data point and the measure […]

Statistical Significance: Mastering the Two-Tailed Test
The Two-Tailed Test in Psychological Research Core Definition and Mechanism The two-tailed test, often referred to as a non-directional test, is a fundamental procedure utilized within statistical test to evaluate the relationship or difference between two groups or variables without specifying the anticipated direction of that effect. In contrast to its directional counterpart (the one-tailed […]

Dichotomy: Understanding the Power of Binary Thinking
Dichotomy in Psychology and Statistics The Core Definition of Dichotomy and Dichotomization The term dichotomy fundamentally describes a division or contrast between two things that are represented as being opposed or entirely different. In a philosophical sense, it implies a separation into two mutually exclusive and exhaustive categories, such as good and evil, nature and […]
Statistical Skewness: Why Your Data Shape Matters
Skewness in Psychological Data The Core Definition of Skewness Skewness, in the realm of descriptive statistics and psychological measurement, is fundamentally defined as the extent of the lack of symmetry in a dataset’s distribution. When data are plotted on a graph, such as a histogram, a perfectly symmetrical distribution would resemble the classic bell shape […]
Symmetrical Distribution: The Blueprint of Balanced Data
Symmetrical Distribution The Core Definition of Symmetrical Distribution A symmetrical distribution is a fundamental concept in statistics and psychological research, defining a data set where the values are equally distributed around a central point. In simplest terms, if a distribution is graphed, and a vertical line is drawn through its center, the resulting shape on […]

Statistical Aliasing: Unmasking Hidden Research Biases
Aliasing in Psychological Research and Experimental Design Defining Aliasing in Psychological Research Aliasing, particularly within the context of psychological research and statistical analysis, refers to a critical methodological flaw where the estimated effect of one variable is inextricably mixed or superimposed upon the estimated effect of one or more other variables. This phenomenon renders the […]

Somers’ D: Mastering Ordinal Association in Psychology
Somers’ D: Asymmetric Measure of Association The Core Definition of Somers’ D Somers’ D is a fundamental statistical tool in psychology and social sciences, defined precisely as an asymmetric measure of association between two variables that are measured on an ordinal scale. Unlike symmetric measures which treat both variables equally, Somers’ D explicitly distinguishes between […]
F-Distribution: Mastering Statistical Significance
The F Distribution in Statistics and Psychology Core Definition and Mathematical Foundation The F distribution, often referred to as the Snedecor’s F distribution or the F-ratio, is a fundamental continuous probability distribution utilized extensively in statistical inference, particularly within the social sciences and experimental psychology. At its core, the F distribution describes the distribution of […]
Statistical Outliers: Why Anomalies Shape Human Behavior
Outlier: Extreme Observations in Psychological Research The Core Definition of an Outlier An Outlier is formally defined as an extreme observation, measurement, or rating, which substantially deviates from the bulk of other data points within a given sample or distribution. In the context of psychological research and quantitative analysis, an outlier is a data point […]

Bipolar Factor: Mapping the Duality of Human Personality
Bipolar Factor in Psychometrics The Core Definition of the Bipolar Factor The Bipolar Factor, a concept fundamental to multivariate statistics and Psychometrics, refers to a variable or dimension derived through techniques such as Factor Analysis, which is characterized by the presence of two diametrically opposed poles. Unlike a unipolar scale that ranges from zero to […]
Probability Density Functions: Mapping Human Behavior
Probability Density Functions in Psychological Measurement The Core Definition: Modeling Psychological Variables A Probability Density Function (PDF) is a fundamental statistical tool used in psychology to mathematically describe the relative likelihood of a continuous random variable taking on a specific value. While the concept originates in pure mathematics and statistics, its application in psychological research […]

Ratio Scale: The Gold Standard of Measurement
Ratio Scale The Core Definition of the Ratio Scale The ratio scale represents the highest and most informative level of measurement within the framework of quantitative research, particularly vital within fields like psychometrics and experimental psychology. Fundamentally, a ratio scale not only categorizes and orders data, and possesses equal intervals between units, but it also […]

Randomized Sampling: Mastering Data Selection in Research
TABLE OF RANDOM NUMBERS Introduction and Core Definition The concept of the Table of Random Numbers (TRN) in psychological research methodology refers to a collection of digits, often grouped in five or ten, where each digit has been generated independently and possesses an equal probability of appearing at any point within the table. This methodological […]

The T-Test: Proving Significance in Research Data
The T-Test: A Foundation of Inferential Statistics The Core Definition and Mechanism The t-test stands as a fundamental tool within the realm of inferential statistics, serving the critical function of determining whether the difference between the observed means of two distinct groups is statistically significant or merely the product of random chance and sampling variability. […]

Dichotomous Variables: Decoding Binary Data in Psychology
The Dichotomous Variable in Psychological Research The Core Definition and Mechanism of Dichotomy A dichotomous variable, often referred to interchangeably with a binary variable, is fundamentally a type of categorical variable that possesses exactly two mutually exclusive and exhaustive categories or levels. This constraint means that any given observation must fall into one of the […]

Regression Coefficients: Decoding Behavioral Predictions
The Regression Coefficient in Psychological and Statistical Modeling The Core Definition and Mechanism of Regression Coefficients The concept of the Regression Coefficient is fundamental to the field of inferential statistics, serving as a critical parameter within Linear Regression models. At its most basic level, a regression coefficient is a numerical value that quantifies the strength, […]
Contingent Probability: Predicting Human Behavior Patterns
CONTINGENT PROBABILITY IN PSYCHOLOGY AND COGNITION The Core Definition of Contingent Probability Contingent probability, fundamentally known as conditional probability in statistics, describes the likelihood of an event occurring given that a preceding, related event has already taken place. This concept moves beyond simple probability by incorporating known information to refine predictive outcomes. For instance, while […]
Normal Distribution: Mapping the Human Mind
The Bell Curve: Normal Distribution in Psychology and Statistics The Core Definition of the Bell Curve The bell curve, formally known as the normal distribution or Gaussian distribution, is a foundational statistical concept used extensively across the sciences, including psychology, to describe and predict the probability of events. It represents a continuous probability distribution for […]
Data Recoding: Mastering Psychological Data Transformation
Recoding in Psychological Research and Data Analysis The Core Definition of Recoding Recoding, in the context of statistical data analysis within psychology, is fundamentally a data-processing technique that systematically changes or transforms the existing values of a dataset. At its most basic level, it involves modifying raw data points into a new, more manageable format […]
Categorical Variables: Unlocking Meaning in Human Data
Categorical Variables in Psychological Research The Core Definition of Categorical Variables A categorical variable, often referred to as a qualitative variable, is a fundamental concept in statistics and psychological research, defined as a variable whose values represent groups or categories. Crucially, these values do not possess any inherent numerical or quantitative meaning in terms of […]

Tetrachoric Correlation: Unlocking Latent Data Patterns
TETRACHORIC CORRELATION The Core Definition of Tetrachoric Correlation The Tetrachoric Correlation coefficient, typically denoted as $rho_t$, is a specialized measure used in statistics and psychometrics to estimate the correlation between two theoretical continuous variables, assuming both variables follow a bivariate normal distribution. This estimation becomes necessary when, due to methodological constraints, practical observation, or intentional […]

Random Variables: Decoding Human Behavior Through Data
The Random Variable in Psychology and Statistics The Core Definition of a Random Variable A Random Variable is a fundamental concept in both probability theory and statistics, serving as the crucial link between the abstract outcomes of a random phenomenon and the numerical data analyzed by researchers. Simply put, a random variable is a numerical […]
Marginal Frequency: Decoding Human Behavioral Patterns
Marginal Frequency: A Comprehensive Overview Marginal frequency is a concept widely used in statistics and probability theory. It is used to describe the number of occurrences of an event or a set of events in a given population. It is usually expressed as a percentage of the total number of occurrences in the population. The […]

Psychological Derangement: Understanding Mental Chaos
Derangement in Clinical Psychology Introduction: Defining Psychological Derangement The term Derangement, while largely considered an antiquated term in contemporary psychiatry, describes a profound and comprehensive disturbance of the mental faculties, suggesting a state where the normal organization and function of the mind have become fundamentally disordered. Historically, it served as a broad classification for severe […]
Statistical Modeling: Beyond R-Squared Accuracy
Adjusted R-squared (Adjusted $text{R}^2$) The Core Definition of Adjusted R-squared The Adjusted R-squared statistic is a critical metric utilized primarily in the realm of Linear Regression Model analysis. Fundamentally, it serves as a sophisticated modification of the standard Coefficient of Determination (R²), designed specifically to provide a more honest and reliable assessment of a model’s […]

Correlation Ratio: Mastering Non-Linear Data in Psychology
The Correlation Ratio ($eta$): A Measure of Association in Psychology The Core Definition of the Correlation Ratio The Correlation Ratio (often symbolized by the Greek letter eta squared, $eta^2$) is a powerful statistical measure of association that quantifies the relationship between two variables when one is a categorical variable (nominal or ordinal) and the other […]

Regression toward the Mean: Why Exceptional Trends Fade
Regression toward the Mean: A Statistical Phenomenon with Relevance to Everyday Life Abstract This article provides an overview of regression toward the mean (RTM), a statistical phenomenon that has been studied and discussed since the late 19th century. The article presents an overview of the concept, its history, and its implications in everyday life. The […]
Quantitative Modeling: Mapping Patterns in Human Behavior
CURVE FITTING Introduction to Curve Fitting Curve fitting is a fundamental mathematical and statistical technique employed across various scientific and engineering disciplines, including psychology, to identify the most appropriate mathematical function that describes the relationship between a set of observed data points. At its core, it involves finding a “best fit” line or curve that […]

Discrete Measurement: Quantifying the Human Experience
Discrete Measure The Core Definition of Discrete Measure Discrete measure is a fundamental mathematical concept employed to describe situations where quantities can be counted in distinct, separate units rather than measured along a continuous spectrum. Unlike measurements that can take on any value within a given range, discrete measurements are characterized by their clear, individualized […]

Mutually Exclusive Events: Why They Cannot Coexist
Mutually Exclusive Events: A Comprehensive Overview Y.H. Chiang and K.L. Chang Department of Statistics, National Chengchi University, Taipei City, Taiwan Abstract Mutually exclusive events are events that cannot occur simultaneously. These events are important in many areas of probability and statistics, such as finding the probability of at least one event occurring, calculating the probability […]

Discrete Data: Counting the Building Blocks of Human Behavior
Discrete Data The Core Definition of Discrete Data Discrete data constitutes a fundamental type of data characterized by its distinct, separate, and countable values. Unlike data that can theoretically assume any value within a given range, discrete data is constrained to a finite or countably infinite set of specific, isolated points. Each value stands alone, […]
Data Visualization: Mapping the Landscape of Human Thought
Stem-and-Leaf Plot The Core Definition of Stem-and-Leaf Plots A stem-and-leaf plot is an innovative and highly intuitive graphical display used in descriptive statistics to organize and present quantitative data. At its most fundamental level, it serves as a hybrid visualization tool, combining the visual impact of a graph with the precision of a table, by […]

Statistical Regression: Mapping Patterns in Human Behavior
Regression Line Introduction: The Core Definition In the expansive realm of statistics, a regression line stands as a fundamental analytical tool, meticulously designed to quantify and visualize the relationship between two variables. At its most basic, it is a straight line that best represents the general trend of the data points observed in a given […]
Bimodal Distribution: Understanding Human Mental Divergence
Abstract This article provides an overview of bimodal distribution, a type of probability distribution that has two distinct peaks. We discuss the properties of bimodal distributions, their application in various fields, and the methods used to estimate parameters when fitting a bimodal distribution to data. We also review some of the challenges associated with interpreting […]
Probability Distributions: Predicting Human Behavior
Probability Mass Function Introduction to Probability Mass Function (PMF) The Probability Mass Function (PMF) stands as a fundamental concept within the realms of probability theory and statistics, serving as an indispensable tool for characterizing discrete random variables. At its core, a PMF is a specialized type of probability distribution that meticulously assigns a distinct probability […]
NONCCNTRAL CHI-SQUARE DISTRIBUTION
Introduction to the Noncentral Chi-Square Distribution The noncentral Chi-square distribution represents a sophisticated extension of the standard Chi-square distribution, serving as a fundamental pillar in the architecture of modern inferential statistics. While the central Chi-square distribution is primarily utilized to evaluate data under the assumption that a null hypothesis is true, the noncentral variant is […]
PROBABILITY THEORY
The Conceptual Framework of Probability Theory Probability theory serves as the fundamental mathematical architecture for analyzing and interpreting random phenomena. At its core, this discipline seeks to quantify the likelihood of various outcomes in systems where the results are not deterministic. By providing a rigorous language for uncertainty, probability theory allows researchers and practitioners to […]
MARBE’S LAW
Origins and the Würzburg School Context The conceptual genesis of Marbe’s Law is deeply rooted in the experimental traditions of the late nineteenth and early twentieth centuries, specifically within the influential Würzburg School of psychology. Karl Marbe, a German psychologist who was a contemporary of figures like Oswald Külpe, sought to move beyond the purely […]
NORMAL DISTRIBUTION
Introduction to the Foundations of the Normal Distribution The normal distribution, frequently referred to in academic circles as the Gaussian distribution, stands as perhaps the most significant and foundational concept within the realms of modern statistics, mathematics, and the behavioral sciences. This continuous probability distribution is characterized by its perfectly symmetrical, bell-shaped profile, which represents […]
PROBABILITY
The Conceptual Foundations of Probability Theory At its most fundamental level, probability serves as the primary mathematical instrument for quantifying the likelihood of specific outcomes within a defined set of circumstances. It represents the formal study of randomness and uncertainty, providing a structured framework through which we can interpret events that are not inherently deterministic. […]
BERNOULLI TRIAL
Historical Foundations and Conceptual Origins of the Bernoulli Trial The Bernoulli trial serves as one of the most fundamental building blocks in the fields of probability theory and statistics. Named after the Swiss mathematician Jacob Bernoulli (though often associated with the broader Bernoulli family including Daniel Bernoulli), this concept describes an experiment in which there […]
CONDITIONAL PROBABILITY
The Fundamental Principles of Conditional Probability Conditional probability serves as a cornerstone of modern statistical analysis and probability theory, providing a rigorous framework for understanding the likelihood of an event occurring under the specific stipulation that another event has already taken place. Unlike marginal probability, which examines the likelihood of an event in isolation, conditional […]
DECILE
DECILE In the expansive field of quantitative psychology and statistical analysis, the concept of a decile serves as a fundamental metric for understanding the relative positioning of data points within a larger distribution. A decile is defined as a specific type of quantile that partitions a ranked data set into ten equal parts, with each […]
SAMPLE SPACE I
Conceptual Foundations of Sample Space I In the expansive domain of probability theory and statistical analysis, the concept of Sample Space I serves as the fundamental bedrock upon which all subsequent calculations and theoretical constructs are constructed. At its most basic level, Sample Space I represents the exhaustive set of all potential outcomes that could […]
DISCRETE VARIABLE
Definition and Fundamental Characteristics of Discrete Variables A discrete variable constitutes a crucial classification within the realm of statistics, mathematics, and data science, defined by its capacity to assume only a finite or countably infinite number of values. Unlike their continuous counterparts, discrete variables possess inherent gaps between potential values, meaning that the observations they […]
CORRELATION
Introduction to Correlation in Research In the expansive field of psychological and social research, the concept of correlation stands as a foundational statistical tool used to quantify the relationship between two or more measurable variables. This statistical technique provides researchers with a robust method for determining whether changes observed in one variable consistently coincide with […]
SAMPLING ERROR
Introduction to Sampling Error Sampling error constitutes a foundational concept within the field of statistics and quantitative research methodology, particularly when researchers attempt to derive conclusions about a large target group based solely on the examination of a subset. This error inherently arises because analyzing an entire population, often due to constraints of time, cost, […]
UNIFORM DISTRIBUTION
Introduction to Uniform Distribution The uniform distribution stands as one of the most fundamental concepts within the theory of probability and statistics, defining a scenario where every potential outcome across a defined range is equally probable. This inherent characteristic of perfect impartiality makes it a cornerstone for modeling numerous real-world phenomena where bias or weighting […]
FREQUENCY POLYGON
Introduction and Definition The frequency polygon stands as a fundamental statistical tool specifically designed for the visual representation of data distribution. In the rigorous domain of quantitative analysis, transforming raw numerical data into an accessible graphical format is paramount, enabling researchers to quickly discern underlying patterns, trends, and the general shape of the dataset. A […]
MEDIAN
Introduction to the Median and Central Tendency The concept of the median stands as a foundational element within mathematics and descriptive statistics, serving as a powerful and indispensable measure of central tendency. Fundamentally, the median is defined as the exact midpoint of a dataset when the values are ordered sequentially. Its primary function is to […]
BINOMIAL DISTRIBUTION
BINOMIAL DISTRIBUTION: AN INTRODUCTION TO DISCRETE PROBABILITY The binomial distribution stands as a cornerstone of probability theory, providing a critical framework for modeling situations where outcomes are strictly binary and trials are conducted independently. It is fundamentally a discrete probability distribution, meaning that the variable being measured—the number of successes—can only take on a finite […]