
Chronic Pain: Decoding the Psychology of Opioid Dependence
The Psychology of Chronic Pain Management and Opioid Dependence The Core Definition of Pain from a Psychological Perspective The psychological study of pain management explores the intricate, subjective experience of discomfort and suffering, particularly when it transitions into a chronic state lasting more than three to six months. Pain is fundamentally defined not merely as […]
Dale’s Principle: Decoding Chemical Signaling in the Brain
The Dale Principle and Neurotransmitter Co-Release The Core Definition of Dale’s Principle The concept widely, and often inaccurately, referred to as Dale’s Law is more correctly known today as the Dale Principle. This principle, which dominated neuroscientific thought for decades, posited a fundamental mechanism of chemical communication within the nervous system: that a mature neuron […]

Decarceration: Rethinking Freedom and Human Potential
Decarceration: Shifting Paradigms in Criminal Justice and Psychology The Core Definition of Decarceration Decarceration is fundamentally a sociopolitical and psychological movement aimed at reducing the number of individuals confined in correctional institutions, primarily prisons and jails, through various means of supervised release, diversion, and community-based alternatives. In its simplest form, it signifies the process where […]

Signal Detection: Mastering the Art of Discernment
D Prime (d’) in Signal Detection Theory The Core Definition of D Prime D Prime, often symbolized as $d’$, stands as the fundamental measurement within Signal Detection Theory (SDT), a framework designed to quantify how accurately an observer can differentiate between informational signals and background noise. In its simplest form, D Prime is a gauge […]

Debilitative Anxiety: Overcoming Your Mental Blocks
Debilitative Anxiety: Definition, Mechanisms, and Impact on Performance The Core Definition of Debilitative Anxiety Debilitative Anxiety is defined as a specific type of anxiety experienced by an individual that is perceived subjectively as detrimental to their ability to execute a task effectively or achieve a desired outcome. Unlike generalized anxiety, which may be pervasive but […]

Deaggressivization: Channeling Your Inner Drive for Success
noun. With regard to psychoanalytic theory, the neutralizing of urges of aggression so that its energy can be veered in the direction of many jobs and desires of the ego. DEAGGRESSIVIZATION: “Deaggressivization is a way of neutralizing aggression in people, not to inhibit such specifically, but so that energy reserves spent on such an emotion […]

Structured Intermittent Intervention: A Developmental Tool
Day Camp: A Psychological Perspective on Structured Intermittent Intervention The Core Definition and Mechanism The concept of a day camp, within the context of developmental and clinical psychology, refers to an organized, temporary institution that delivers structured academic, recreational, and often specialized rehabilitative services to children and adolescents on a regular, intermittent daily schedule. Crucially […]

Dementia Diagnostics: Understanding DAT and Clinical Impact
1. abbreviated form of the Alzheimer’s form of dementia. 2. abbreviated form of Differential Aptitude Tests. DAT 1: “Dave was saddened to hear of his mother’s diagnosis with DAT.”
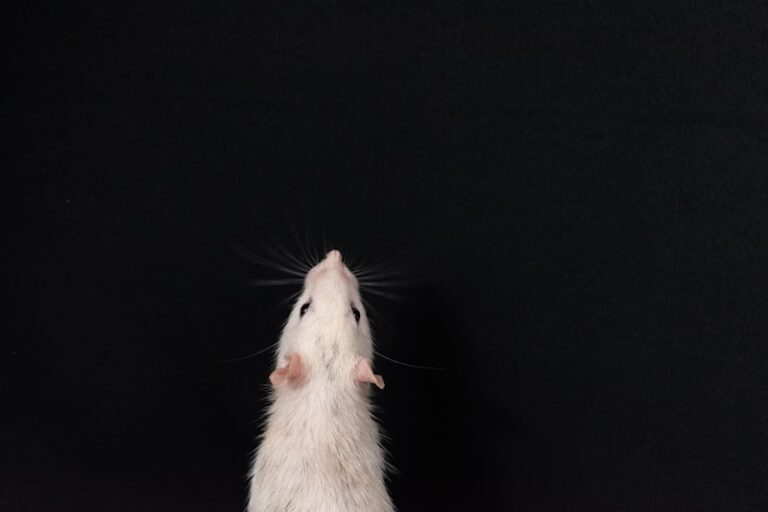
Vestibular Dysfunction: Why Mice Dance to the Beat
a group of mice demonstrating behavior similar to dancing. They possess a genetic fault wherein deterioration of hair cells occurs in the inner ear, generating loss of audile abilities and handicapped operations of the vestibular system of the ear, thereby eliciting the dancing. DANCING MOUSE: “A dancing mouse will often run forward to backward in […]

Deautomatization: Regain Conscious Control of Your Mind
The Deautomatization Hypothesis The Core Definition and Mechanism The Deautomatization Hypothesis is a fundamental concept in Cognitive Psychology that suggests highly practiced, non-conscious, and efficient mental operations—known collectively as automaticity—can be deliberately interrupted and brought back under conscious, voluntary control. In essence, it describes the reversal of the learning process that turns effortful actions into […]

Auditory Impairment: Navigating the Silent Psychological Realm
Deafness: A Comprehensive Psychological Entry The Core Definition of Deafness Deafness, in its most fundamental description, refers to the partial or total inexistence of the auditory sense, resulting in the diminished or complete inability to hear sound. This condition exists on a wide spectrum, ranging from mild hearing loss, where soft sounds are difficult to […]
Hemeralopia: Why Bright Light Blurs Your Vision
Hemeralopia: An Encyclopedia Entry on Day Blindness The Core Definition of Hemeralopia Hemeralopia, commonly known as day blindness, is a visual disorder characterized by an irregular and debilitating vulnerability of the visual system, particularly the fovea centralis, to bright light. This condition results in significantly impaired vision, intense glare, and discomfort under photopic (daylight) conditions, […]

Dasein Analysis: Unlocking the Essence of Your Existence
Dasein Analysis The Core Definition of Dasein Analysis Dasein Analysis, often referred to as Existential Analysis, is a profound and specialized technique employed within the framework of existential psychotherapy. The term itself is derived from the German philosophical concept of Dasein, literally meaning “being-there” or “existence.” At its core, Dasein Analysis stresses the requisite for […]

Dance Movement Therapy: Heal Your Mind Through Motion
Dance/Movement Therapy (DMT) The Core Definition of Dance/Movement Therapy Dance/Movement Therapy, often abbreviated as DMT, is the psychotherapeutic use of movement and dance to support the intellectual, emotional, and motor functions of the body. It is fundamentally defined as the utilization of many types of rhythmic motions as a therapy-based method to assist people in […]

Dizygotic Twins: Unlocking the Mystery of Fraternal Bonds
Dizygotic (DZ) Twins Introduction: Defining Dizygotic Twins Dizygotic twins, frequently abbreviated as DZ twins, are fundamentally known as fraternal twins. The term refers to two individuals resulting from the simultaneous yet separate fertilization of two distinct ova (egg cells) by two distinct sperm cells during a single pregnancy cycle. Unlike monozygotic twins, who share 100% […]

Dyspraxia: Understanding the Hidden Motor Challenges
Dyspraxia (Developmental Coordination Disorder) Core Definition of Dyspraxia Dyspraxia, often formally referred to as Developmental Coordination Disorder (DCD), is a chronic neurological condition characterized by an impaired ability to execute skilled and coordinated movements. It is not caused by general intellectual disability or any specific muscle weakness, but rather by difficulties in the brain’s ability […]
Dysosmia: How Olfactory Loss Impacts Your Mind
Dysosmia Introduction and Core Definition Dysosmia is the overarching medical term used to describe any disorder or impairment involving the sense of smell. This condition signifies a breakdown or alteration in the normal functioning of the olfactory system, which is crucial not only for detecting environmental hazards but also for contributing significantly to the perception […]
Dysgenic Pressure: Understanding Trends in Human Cognition
Dysgenic Pressure The Core Definition of Dysgenic Pressure Dysgenic pressure is a theoretical concept originating in demographic studies and behavioral genetics that posits a gradual, generational decline in the average genetic quality of a population for specific traits, most commonly focusing on cognitive ability or intelligence. This pressure is hypothesized to occur when subgroups possessing […]

Dysarthria: Understanding the Mechanics of Speech Loss
Dysarthria: A Comprehensive Overview of a Motor Speech Disorder The Core Definition of Dysarthria Dysarthria is formally defined as a group of motor speech disorders resulting from impairment in the central or peripheral nervous system that affects the muscles responsible for speech production. This neurological condition impacts the precision and coordination required for effective communication, […]

Dynamic Formulation: Unlocking Your Client’s Potential
The attempt to organise a clients information so the therapist can better treat and understand the client. DYNAMIC FORMULATION: “Joe’s therapist used the dynamic formulation to treat his problems better.”

Dustbowl Empiricism: Data Over Theory in Psychology
The approach to science and social science consisting of making empirical observations and collecting data rather than establishing a theoretical framework. DUSTBOWL EMPIRICISM: “The dustbowl empiricism approach was widespread in the centre of the US known as the dustbowl.”

Procedural Justice: Ensuring Fairness in Mental Health
Due Process: Legal Safeguards in Psychological Contexts The Core Definition of Due Process Due Process is a fundamental constitutional guarantee ensuring that the government, in all its actions, must respect the legal rights and safeguards owed to every citizen. It is the administration of law according to the accepted and established principles of fairness, justice, […]

Dual Coding Theory: Boost Learning with Visuals
DUAL CODING THEORY The Core Definition of Dual Coding Theory The Dual Coding Theory (DCT) is a foundational theory in cognitive psychology proposing that human cognition operates through two distinct, but interconnected, mental systems for processing information: one specializing in non-verbal imagery and the other specializing in language. At its most fundamental level, DCT suggests […]

Disorganized Attachment: Understanding the Fear-Bond Cycle
Disorganized Attachment Core Definition of Disorganized Attachment Disorganized attachment, often designated as Type D or sometimes termed Disoriented Attachment, represents a specific and highly concerning pattern of attachment behavior observed primarily in infants and toddlers during interactions with their primary caregivers. It is categorized under the broader umbrella of insecure attachment, but unlike the avoidant […]

Disinformation: The Psychology of Calculated Deception
Disinformation The Core Definition of Disinformation Disinformation is formally defined as false information or propaganda that is deliberately created and publicly announced with the explicit intent to deceive or mislead an audience. Unlike mere error or mistake, the defining characteristic of disinformation rests entirely on the element of malicious intent. It is a calculated act […]

Group Dynamics: Mastering the Art of Influential Leadership
The Role of the Discussion Leader in Group Dynamics The Core Definition of the Discussion Leader The Discussion Leader, in the context of Group Dynamics and social psychology, is formally defined as a designated or emergent group member whose primary function is to guide, structure, and optimize communication among participants toward achieving a specific collective […]

Discriminability: Mastering the Art of Seeing Differences
Discriminability in Psychology The Core Definition of Discriminability The term discriminability in psychology refers fundamentally to the ability of an organism—human or animal—to perceive, recognize, and respond differentially to two or more distinct stimuli. At its most basic level, it is the measurement of how easily or reliably two sensations, perceptions, or features can be […]

Discordance: Why Identical Twins Think Differently
Discordance in Psychology and Genetics The Core Definition of Discordance Discordance, in the context of psychological and behavioral genetics research, refers specifically to the condition where two individuals, particularly genetically similar pairs such as twins, differ with respect to a specific trait, disease, or behavioral outcome. This concept stands in direct contrast to concordance, which […]

Systemic Disadvantage: Breaking the Cycle of Inequality
The Psychological and Social Dynamics of Disadvantage The Core Definition of Disadvantage The term “disadvantaged” refers broadly to individuals, groups, or families who are deprived of essential access to resources, opportunities, and societal necessities required for optimal functioning and well-being within a given society. This deprivation is typically systemic, stemming from structural inequalities rather than […]

Direction Perception: Navigating Your World with Precision
Ability to find a moving target in space or a sound. DIRECTION PERCEPTION: “Direction perception allows us to find a sound or object in space around us.”

Direct Coping: Master Stress Through Proactive Action
Direct Coping The Core Definition of Direct Coping The concept of direct coping refers fundamentally to the active and focused confrontation and management of a stressful situation. Unlike forms of coping that involve avoidance, denial, or emotional suppression, direct coping is characterized by conscious behavioral or cognitive efforts aimed at altering the stressor itself or […]

Juvenile Dependency: Understanding the Courts that Protect
The Psychology and Function of the US Dependency Court System The Core Definition of Dependency Court The Dependency Court, often referred to as Juvenile Dependency Court, is a specialized civil court within the United States judicial system dedicated solely to protecting children who have experienced abuse, abandonment, or neglect. This court operates under the legal […]
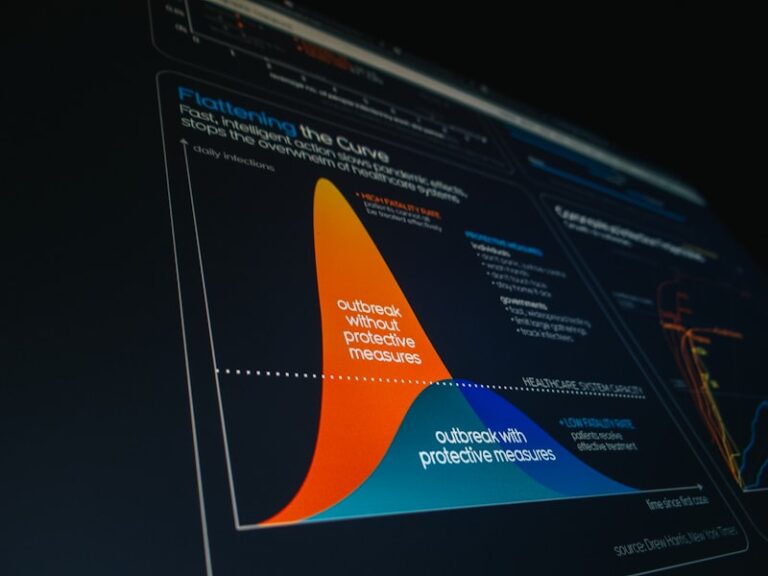
Probability Density Functions: Mapping Human Behavior
Probability Density Functions in Psychological Measurement The Core Definition: Modeling Psychological Variables A Probability Density Function (PDF) is a fundamental statistical tool used in psychology to mathematically describe the relative likelihood of a continuous random variable taking on a specific value. While the concept originates in pure mathematics and statistics, its application in psychological research […]
Demyelinating Disease: When the Brain Loses Its Insulation
Demyelinating Diseases: Definition, Context, and Impact The Core Mechanism of Demyelinating Diseases Demyelinating diseases represent a heterogeneous collection of medical conditions characterized fundamentally by damage to the Myelin sheath, the protective fatty layer insulating nerve cell projections, known as axons. This sheath, composed primarily of lipids and proteins, is crucial for the efficient and rapid […]

Dementia Rating Scales: Measuring Cognitive Decline
DEMENTIA RATING SCALES: Assessment of Cognitive and Functional Decline The Core Definition and Purpose Dementia Rating Scales (DRS) are specialized, standardized psychometric instruments designed to objectively measure the degree and nature of cognitive decline and functional impairment associated with various forms of dementia. These scales provide a quantitative method for assessing deficits across multiple cognitive […]

Delusion of Poverty: When Wealth Becomes a False Fear
Delusion of Poverty Definition and Core Characteristics The Delusion of Poverty (also known historically as Agyrophobia in some obsolete contexts, though this is misleading) is a specific type of fixed, false belief concerning a person’s financial standing. It is classified as a somatic or nihilistic delusion, characterized by the absolute conviction that the individual is […]

Deliriants: Unmasking the Psychology of Hallucination
Deliriants: Pharmacology and Psychological Effects The Core Definition of Deliriants Deliriants constitute a specialized class of psychoactive substances characterized by their capacity to induce a state of profound delirium, which is pharmacologically and experientially distinct from the effects produced by classical psychedelics or dissociatives. Fundamentally, a Deliriant disrupts the brain’s ability to maintain cognitive clarity, […]

The Sleeper Effect: Why Messages Grow Stronger With Time
Delayed Effect The Core Definition of Delayed Effect The concept of the Delayed Effect, often referred to in the context of persuasion as the Sleeper Effect, describes a counterintuitive phenomenon where the impact of a message or stimulus increases over time rather than decreasing. In typical learning and communication models, the influence of new information, […]

Psychological Deification: The Path to Inner Wholeness
Deification (Psychological Concept) The Core Psychological Definition The concept of psychological deification, distinct from its theological or mythological origins, refers to a profound internal process wherein the individual strives for or achieves a state of perceived psychological wholeness, ultimate self-realization, or transcendent integration. It is not about becoming a literal god, but rather about the […]

Cognitive Dissonance: Master Your Inner Conflict
Cognitive Dissonance The Core Definition of Cognitive Dissonance Cognitive dissonance, a foundational concept within modern social psychology, refers to the state of mental stress or discomfort experienced by an individual who simultaneously holds two or more conflicting beliefs, values, or attitudes, or when their actions contradict their core beliefs. This tension arises because humans possess […]
Defense Reflex: How Your Brain Triggers Survival Instincts
Defense Reflex Introduction and Core Definition The defense reflex, fundamentally rooted in biological survival, is defined as a rapid, involuntary, and largely automatic physiological response triggered by a potentially harmful or noxious stimulus. Its primary function is the preservation of the organism, ensuring immediate withdrawal from danger or preparation for imminent threat. This reflex operates […]
Duchenne Smile: The Science of Your Most Authentic Joy
DUCHENNE SMILE Definition and Core Characteristics The Duchenne Smile is universally recognized within psychological science as the definitive, involuntary expression of genuine, positive emotion, such as joy or authentic happiness. Unlike volitional or “social” smiles, which can be manufactured simply by controlling the mouth, the Duchenne Smile is characterized by the simultaneous contraction of two […]

Dual-Career Dynamics: Thriving in the Balancing Act
Dual Career Households: A Psychological Perspective The Core Definition and Scope A dual-career household refers to a family unit where both adult partners pursue professional careers that typically involve high levels of commitment, continuous professional development, and the pursuit of advancement, while simultaneously maintaining shared responsibility for domestic and parental duties. This structure, which has […]

Educational Dropout: Unlocking the Psychology of Withdrawal
The Dropout Phenomenon: Educational and Clinical Perspectives Core Definition and Mechanisms The term dropout, within the context of psychology and educational research, refers fundamentally to the premature cessation of participation in a structured program, most commonly the withdrawal from formal schooling or higher education before the intended completion point or degree attainment. This phenomenon is […]

Dressing Apraxia: The Hidden Mind-Body Disconnect
Dressing Apraxia: A Comprehensive Encyclopedia Entry The Core Definition and Mechanism of Dressing Apraxia Dressing apraxia (DA) is fundamentally a specific neurological deficit characterized by the inability to dress oneself independently despite intact motor function, comprehension, and muscle strength. It is not an issue of paralysis or weakness, nor is it a failure to understand […]

Dread: Understanding the Psychology of Anticipatory Fear
The Psychology of Dread: Anticipatory Fear and Apprehension Core Definition and Differentiation from Anxiety Dread, in psychological terminology, is a profoundly intense and specific negative emotion characterized by overwhelming apprehension regarding a future event perceived as threatening or inescapable. While often confused with generalized anxiety, dread is typically focused on a known, specific timeline or […]

The Down Through Process: Uncover Your Core Motivations
The “Down Through” Process in Psychological Inquiry Introduction and Core Definition of the “Down Through” Process The “Down Through” process, primarily utilized within the field of Neuro-Linguistic Programming (NLP) and various coaching methodologies, is a specialized technique designed to uncover the deeply held core values and ultimate motivations underlying a person’s specific goals, beliefs, or […]

Double Bind: The No-Win Trap That Ruins Your Sanity
DOUBLE BIND The Core Definition of the Double Bind The Double Bind is fundamentally a communication paradox wherein an individual—often a child or a subordinate—receives two or more conflicting messages, rendering a successful response impossible regardless of the choice made. This paradoxical situation ensures that obeying one command inherently means disobeying the other, trapping the […]
Cognitive Dissonance: Why Your Brain Loves to Rationalize
Cognitive Dissonance Theory Introduction: Defining Cognitive Dissonance Cognitive dissonance is a powerfully motivating psychological state of tension that arises when an individual simultaneously holds two or more conflicting cognitions, beliefs, values, or ideas. The core definition posits that humans are not only rational beings but, more importantly, rationalizing beings, possessing an innate drive toward maintaining […]
Cognitive Dissonance: Why Your Brain Hates Contradictions
Cognitive Dissonance Theory The Core Definition of Cognitive Dissonance The concept of Cognitive Dissonance is defined as the mental stress or discomfort experienced by an individual who holds two or more contradictory beliefs, ideas, or values, or when they perform an action that conflicts with their established attitudes. This psychological phenomenon is not merely an […]

Dominance Aggression: The Hidden Power Dynamics of Behavior
Dominance Aggression The Core Definition of Dominance Aggression Dominance aggression is defined as any aggressive behavior aimed at establishing, maintaining, or elevating an individual’s position within a social hierarchy. This type of aggression is fundamentally functional, serving not merely to inflict harm, but rather to communicate power differentials and secure access to critical resources and […]

Divided Attention: The Myth of Multitasking
Divided Attention The Core Definition of Divided Attention Divided attention, often referred to as multitasking, is a fundamental concept in cognitive psychology describing the ability of the human mind to process two or more simultaneous streams of information or execute two or more distinct tasks concurrently. It is not merely switching quickly between tasks, but […]
Dolichocephaly: Decoding the Psychology of Skull Shape
Dolichocephalic The Core Definition of Dolichocephaly The term dolichocephalic, derived from the ancient Greek words dolichos (meaning “long”) and kephalē (meaning “head”), is a descriptive classification used primarily in physical anthropology and craniology to characterize a specific shape of the human skull. Fundamentally, a dolichocephalic skull is one that is notably longer from the front […]

Statistical Modeling: Decoding Error in Psychological Data
Disturbance Term, Residual Term, and Error Variance in Psychological Modeling The Core Definition and Fundamental Mechanisms The concepts of the disturbance term, the residual term, and error variance are fundamental pillars within quantitative psychology and statistical modeling, particularly when researchers attempt to predict outcomes or establish relationships between variables. At its core, the presence of […]

Distractibility: Reclaim Your Focus and Master Your Mind
Distractibility Definition and Core Mechanism Distractibility, in psychological terms, is defined as the susceptibility to having one’s attention diverted from a primary task or focus by irrelevant, competing stimuli in the environment or internal thought processes. It is fundamentally a failure of selective attention—the cognitive mechanism responsible for filtering out noise and maintaining concentration on […]

Spatial Cognition: Mapping How We Perceive Distance
DISTAL: A Novel Distance-Sensitive Learning Algorithm The Core Definition of DISTAL The acronym DISTAL stands for a novel Distance-Sensitive Learning algorithm, developed within the domain of machine learning and computational intelligence. At its heart, DISTAL is an advanced classification mechanism designed to enhance predictive accuracy by meticulously integrating the spatial relationships, or distances, between individual […]

Directive Discipline: Mastering Clear Boundaries for Growth
Directive Discipline: Principles, Practice, and Impact The Core Definition of Directive Discipline Directive discipline is fundamentally a proactive and positive framework designed to guide individuals, particularly children, toward appropriate behavior through the establishment of clear, consistent expectations and instructions. It operates on the principle that confusion and ambiguity often lead to non-compliance, and therefore, providing […]

Disorganized Speech: Unraveling the Logic of Chaos
Disorganized Speech: Definitions, Assessment, and Clinical Relevance The Core Definition of Disorganized Speech Disorganized speech, often referred to synonymously with formal thought disorder, constitutes a critical and complex symptom in clinical psychopathology, primarily recognized as one of the fundamental positive symptoms of schizophrenia. At its most fundamental level, it is defined as a disturbance in […]

Diseases of Adaptation: When Stress Becomes Illness
DISEASE OF ADAPTATION The Core Definition of Disease of Adaptation The concept of “disease of adaptation” is a critical theoretical framework used in medicine and psychology to describe a spectrum of physical and mental health conditions that arise not from direct pathogenic invasion, but as a consequence of the body’s prolonged, failed, or excessive attempts […]

Psychological Discovery: Unlocking the Human Mind
The Psychology of Scientific Discovery The Core Definition of Psychological Discovery Discovery within the realm of psychology is fundamentally the process of identifying, articulating, and empirically validating previously unrecognized or unexplained patterns, structures, or mechanisms that govern human and animal behavior, emotion, and cognition. It extends far beyond simple observation; true psychological discovery involves the […]

DBD-NOS: Understanding Complex Behavioral Patterns
Disruptive Behavior Disorder Not Otherwise Specified (DBD NOS) The Core Definition of DBD NOS Disruptive Behavior Disorder Not Otherwise Specified (DBD NOS) served as a critical diagnostic category within the fourth edition of the Diagnostic and Statistical Manual of Mental Disorders (DSM-IV), characterized by a persistent and pervasive pattern of behavior that significantly disrupts the […]
Cognitive Dissonance: Why Your Brain Hates Contradictions
Cognitive Dissonance Theory The Core Definition of Cognitive Dissonance Cognitive Dissonance refers to the powerful, uncomfortable psychological tension experienced by an individual who simultaneously holds two or more conflicting cognitions (beliefs, attitudes, or values), or when their behavior contradicts one of their existing beliefs. This concept posits that humans possess a fundamental, inherent drive toward […]

Affective Discharge: Unlocking Your Emotional Release
Discharge of Affect The Core Definition of Affective Discharge The concept of Affective Discharge refers fundamentally to the process by which accumulated psychic or emotional energy, known generally as Affect, is released or expressed through observable behaviors or internal physiological responses. In its most basic form, it is the mechanism designed to reduce the internal […]

Discriminant Validity: Proving Your Measures Are Unique
Discriminant Validity: Establishing Construct Separation in Psychometrics The Core Definition of Discriminant Validity Discriminant validity is a critical psychometric standard that assesses the extent to which a measure of a theoretical construct is empirically distinct from measures of other constructs that are theoretically related but conceptually separate. In essence, it answers the fundamental question: Is […]

Phonetic Perception: How Vowel Shifts Shape Human Cognition
DIPHTHONG Introduction to Diphthongs and Their Cognitive Significance The concept of the Diphthong is fundamentally a linguistic and phonetic one, defined as a type of speech sound resulting from the combination of two adjacent vowel sounds within the same syllable. Unlike a monophthong, which maintains a single, fixed articulatory position throughout its duration, a diphthong […]

Direct Scaling: Quantifying Human Perception Precisely
Direct Scaling in Psychophysics The Core Definition of Direct Scaling Direct Scaling (DS) is a fundamental methodology within the field of Psychophysics used to measure the perceived intensity of a stimulus directly by relying on subjective judgments provided by human observers. Unlike older, indirect scaling methods that relied solely on detecting thresholds or just noticeable […]

Cognitive Dilemmas: Navigating Your Toughest Choices
The Psychology of Dilemmas Core Definition and Psychological Significance A dilemma, within the context of psychology and decision science, is fundamentally defined as a situation requiring a choice between two or more alternatives that are equally undesirable or equally favorable, yet mutually exclusive. This choice is characterized by significant internal conflict because selecting one option […]

Metabolic Typing: Decoding Your Body’s Unique Needs
Digestive Type (Metabolic Typing) in Health Psychology The Core Definition and Mechanism The concept known as Digestive Type, more formally recognized as Metabolic Typing, represents an approach to nutrition that asserts that dietary requirements must be highly individualized, taking into account a person’s unique biochemistry and genetic predispositions. This perspective fundamentally rejects the widespread “one-size-fits-all” […]
Diaschisis: The Ripple Effect of Brain Injury
Diaschisis: The Phenomenon of Neural Disconnection The Core Definition of Diaschisis Diaschisis, derived from Greek meaning “split condition,” is a profound, yet often subtle, neurological phenomenon characterized by the transient or persistent loss of function in a brain region that is remote from the primary site of injury or lesion. This concept moves beyond the […]

Differential Relaxation: Master Your Calm Under Pressure
Differential Relaxation: A Novel Model for Non-linear Optimization Abstract This paper introduces differential relaxation (DR), a novel optimization model for solving non-linear optimization problems. DR is a gradient-based approach that combines the simplicity of gradient descent with the global optimization abilities of traditional methods such as simulated annealing. We explain the fundamentals of DR and […]

Diagnostic Overshadowing: Why Your Physical Health Matters
Diagnostic Overshadowing The Core Concept and Definition Diagnostic overshadowing is a critical phenomenon observed in clinical settings where physical symptoms presented by an individual are mistakenly attributed to, or entirely disregarded because of, a preexisting or prominent comorbid mental disorder. In essence, the mental health diagnosis acts as a powerful filter through which clinicians interpret […]

Differential Accuracy: Mastering the Art of Social Insight
Differential Accuracy in Psychological Assessment and Social Cognition The Core Definition of Differential Accuracy Differential Accuracy, within the realm of psychological science, refers specifically to an individual’s ability to correctly perceive and track genuine differences among various target persons, situations, or stimuli. Unlike simple overall accuracy, which is merely the total percentage of correct judgments […]

Dichotomous Variables: Decoding Binary Data in Psychology
The Dichotomous Variable in Psychological Research The Core Definition and Mechanism of Dichotomy A dichotomous variable, often referred to interchangeably with a binary variable, is fundamentally a type of categorical variable that possesses exactly two mutually exclusive and exhaustive categories or levels. This constraint means that any given observation must fall into one of the […]
Diabetes Psychology: The Mind-Body Connection in Care
Psychological Dimensions of Diabetes Mellitus The Core Definition: Diabetes Mellitus and Its Psychosocial Context Diabetes Mellitus (DM) is fundamentally a chronic metabolic disorder characterized by high blood sugar levels over a prolonged period, resulting either from the pancreas not producing enough Insulin, or the body’s cells not responding properly to the insulin produced. While the […]

Developmental Psychology: The Blueprint of Human Growth
Developmental Psychology The Core Definition of Developmental Psychology Developmental Psychology is an expansive and interdisciplinary scientific field dedicated to understanding the psychological, cognitive, social, and emotional growth of individuals across the entire lifespan, from conception through old age and death. At its essence, the discipline seeks to chart the systematic, successive, and relatively permanent changes […]

Deviant Behavior: Why We Break the Rules
Deviant Behavior: Causes, Consequences, and Social Dynamics The Core Definition of Deviance Deviant behavior is fundamentally defined as any conduct that significantly violates established social norms, expectations, or rules within a particular society or cultural group. This concept is crucial because it highlights the relativistic nature of “normalcy;” what is deemed deviant in one culture, […]

Deuteranomaly: Decoding Your Unique Spectrum of Vision
Deuteranomaly: A Comprehensive Overview The Core Definition and Mechanism of Deuteranomaly Deuteranomaly is the most prevalent form of inherited Color Vision Deficiency (CVD), often referred to colloquially as “color blindness.” Fundamentally, it involves an abnormal perception of colors, specifically within the red-green spectrum, resulting not in the complete inability to see these colors but rather […]

Descriptive Research: Capturing the Human Experience
Descriptive Research The Core Definition and Fundamental Mechanism Descriptive research is a foundational type of scientific inquiry specifically designed to systematically observe, describe, and document the characteristics of a population, phenomenon, or situation. Unlike experimental studies, which seek to establish cause-and-effect relationships by manipulating variables, descriptive research aims purely to paint an accurate, detailed portrait […]

Cognitive Decline: Measuring Your Brain’s Vitality
The Deterioration Index: A Metric for Quality and Longevity The Core Definition and Fundamental Mechanism The Deterioration Index (DI) is a critical quantitative metric utilized across numerous industries to objectively measure the decline in the condition, performance, or overall value of a physical asset, product, or service over a specified period. Essentially, it provides a […]

Despondency: Escaping the Grip of Persistent Hopelessness
Despondency: A Review of the Psychological Consequences Introduction: Defining Despondency Despondency is a profound psychological state characterized by pervasive feelings of sadness, severe discouragement, and a debilitating sense of overwhelming difficulty. It is conceptually distinct from mild sadness or temporary disappointment in its intensity and duration, signifying a persistent emotional experience often resulting from perceived […]

Dermatoglyphics: What Your Fingerprints Reveal About You
Dermatoglyphics The Core Definition of Dermatoglyphics Dermatoglyphics, derived from the Greek words “derma” (skin) and “glyphe” (carving), is the scientific study of the arrangement of epidermal ridges and their associated flexion creases on the fingers, palms, toes, and soles. These intricate patterns, commonly known as fingerprints, are unique to every individual and form during the […]

Depth Therapy: Unlocking Your Hidden Potential
Depth Therapy The Core Definition and Underlying Mechanisms Depth therapy, often referred to as depth psychology or psychoanalytic therapy, represents an expansive approach to psychotherapy that focuses intensely on exploring the deeper, often hidden layers of the human psyche. At its core, depth therapy posits that significant psychological issues, emotional suffering, and persistent behavioral patterns […]

Depressive Anxiety: Navigating the Overlapping Shadows
Depressive Anxiety: An Integrated Perspective The Core Definition of Depressive Anxiety Depressive anxiety, often clinically referred to as co-morbid anxiety and depression, represents a complex form of psychological distress characterized by the simultaneous presence of significant depressive symptoms and marked anxiety symptoms. This is not simply a transient state of sadness or worry but a […]
Cognitive Dissonance: Why Your Brain Hates Contradictions
Cognitive Dissonance Theory Introduction: The Core Definition The concept of Cognitive Dissonance is one of the most powerful and enduring theories within modern social psychology, providing a fundamental explanation for the often-irrational nature of human motivation and attitude change. At its core, cognitive dissonance describes the profound mental discomfort, or psychological stress, experienced by an […]